別記事の続きです。データの登録と検索について記載します。
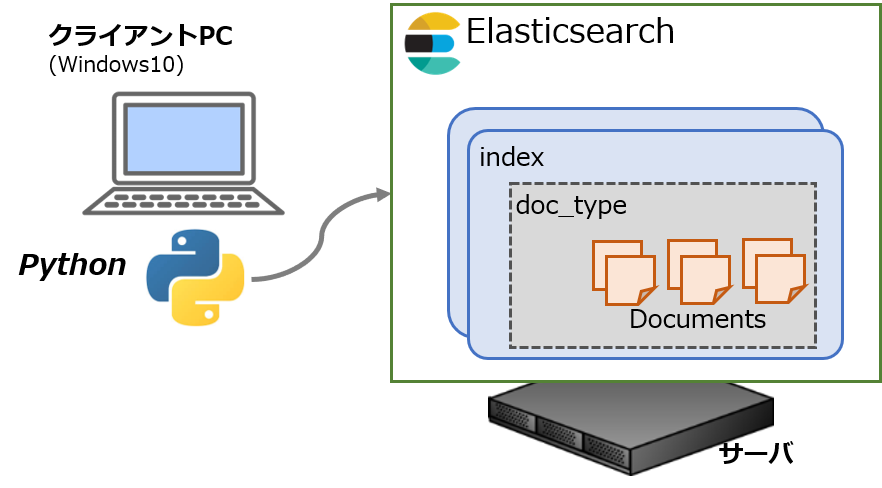
もくじ:
データの投入
Elasticsearch().indexプロパティを経由して、データ(ドキュメント)を登録します。公式には「インデキシング」と呼ばれているようですね。
1 2 3 4 5 6 7 | from elasticsearch import Elasticsearch es = Elasticsearch("{}:{}".format(conf_["host"], conf_["port"])) for item in _load_data(): # ドキュメントの登録 pprint(es.index(index=item["_index"], doc_type=item["_type"], body=item["_source"])) |
データ内にID("_id")を明示していない場合は、サーバ側で自動的に生成されます。また、マッピングを明示していない場合も自動的に定義されます。
上のように逐次的に登録していく方法もありますが、一括で実行することもできます。複雑な操作でなければこちらのほうが高速に実行できますので効率的です。データはリストとして渡すか、メモリに乗らない場合はイテレータを使うやり方が良いでしょう。
この用途のためにhelpersに.bulkメソッドが用意されています。
1 2 3 4 5 | from elasticsearch import Elasticsearch, helpers es = Elasticsearch("{}:{}".format(conf_["host"], conf_["port"])) # bulkインサート pprint(helpers.bulk(es, _load_data())) |
今回はジェネレータ_load_data()を定義し、インデックス名"_index"やドキュメントタイプ名"_type"、ドキュメント"_source"(データ本体)を持つdictオブジェクトを整形してyieldさせています。
1 2 3 4 | def _load_data(index_, type_): src_ = _load_json("data-source.json") for data_ in src_: yield {"_index": index_, "_type": type_, "_source": data_} |
まあ、今回は別途ファイル(データをリストにしたJSONファイル)から全て読んでいるコードなのであまり意味はありませんが、for文の中で別途大きなデータを生成させる場合や、そもそもの件数が多い場合に有効です。
なお、.bulkメソッドに渡すオブジェクトは"_index"や"_type"を省略する場合、"_id"を明示する場合などバリエーションがあります。"_op_type"の設定次第で、ドキュメントの更新や削除など他の操作もできますがここでは割愛します。
検索
クエリを使って検索できます。標準でサポートされているものはQuery DSLと呼ばれているもので、"query"キーを持つオブジェクトで定義するのがよく使われる例です。
特定のフィールド(例の場合は"name")がある値に一致するものを取得するには、下記のように書きます。
1 2 3 | es = Elasticsearch("{}:{}".format(conf_["host"], conf_["port"])) body_ = {"query": {"match": {"name": "ebisugawa"}}} pprint(es.search(index="myindex2", body=body_)) |
マッピングの定義方法にもよりますが、結果は下記のようになりました。"name"フィールドで指定した値を含むものが返ってきていますね。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | {'_shards': {'failed': 0, 'skipped': 0, 'successful': 5, 'total': 5}, 'hits': {'hits': [{'_id': 'SI-gm2QBtWXsLWYD3KED', '_index': 'myindex2', '_score': 0.6931472, '_source': {'category': 'M', 'name': 'Ebisugawa Soun', 'tag': 'tanuki'}, '_type': 'docs'}, {'_id': 'RY-gm2QBtWXsLWYD2qHP', '_index': 'myindex2', '_score': 0.2876821, '_source': {'category': 'F', 'name': 'Ebisugawa Kaisei', 'tag': 'tanuki'}, '_type': 'docs'}], 'max_score': 0.6931472, 'total': 2}, 'timed_out': False, 'took': 37} |
デフォルトでスコアが計算されるようになっていますので、もっと実際的なデータを扱う際にはソートに使うことができます。スコアの詳しい設定はクエリ等の書き方次第で、要件に応じて調整することもできます。
今回は元のドキュメント(_sourceの部分)そのものを応答に含めていますが、ドキュメント単体が大きい場合など、取得するフィールドを絞ることもできます。下記はドキュメントを省略させる場合の例です。
1 | pprint(es.search(index="myindex2", body=body_, _source=False)) |
ヒット数'hits.total'が多い場合、'hits.hits'に入れられるドキュメントはそのうちの一部(デフォルトでは10)になります。ページネーションされているイメージですが、検索のオプション次第で振る舞いを変えることができます。
クエリのバリエーションはそれこそ書ききれないくらい豊富なので、ここではあと一例くらい。And条件で複数のフィールドの一致を指定する場合は、こんなクエリになります。
1 2 3 4 5 6 7 | body_ = {"query": { "bool": { "must": [{"match": {"category": "F"}}, {"match": {"tag": "tanuki"}}] } } } |
結果はこんな感じ。指定したフィールドのAnd部分が返ってきているのがわかります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | { ..., "hits": { "total": 3, "max_score": 1.0498221, "hits": [{ "_index": "...", "_score": 1.0498221, "_source": { "name": "Shimogamo Tousen", "category": "F", "tag": "tanuki" },... }, { "_score": 1.0498221, "_source": { "name": "Nanzenji Gyokuran", "category": "F", "tag": "tanuki" },... }, { "_score": 0.5753642, "_source": { "name": "Ebisugawa Kaisei", "category": "F", "tag": "tanuki" },... } ] } } |
SQL型のデータベースと比較しても機能的にほぼ同等のクエリが書けますし、より柔軟な検索(あいまい検索など)が可能な分、検索機能についての完成度はやはり高いですね。
もちろん、アナライズなどの例と同じく、KibanaのコンソールからWeb APIをたたくこともできますので、オンデマンドに色々試してみるとクエリについての理解が深まると思います。
サンプル
今回のサンプルです。各操作をファンクションに分けて記述していますが、基本的にはElasticsearch()クライアントを生成して各メソッドを呼び出すだけです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 | import json import os import sys from pprint import pprint from traceback import print_exc from elasticsearch import Elasticsearch, helpers conf_ = {"host": "eshost.local", "port": 9200, "index": "myindex", "doc_type": "docs"} def _load_json(file_name): with open(os.path.join("data", file_name)) as f: return json.load(f) def _save_json(obj_, file_name): with open(os.path.join("data", file_name), 'w') as f: json.dump(obj_, f, indent=4, ensure_ascii=False) def get_info(): es = Elasticsearch("{}:{}".format(conf_["host"], conf_["port"])) pprint(es.info()) pprint(es.nodes.info()) pprint(es.indices.get(index="*")) pprint(es.indices.stats(index="*")) def test_analyze(phrase): es = Elasticsearch("{}:{}".format(conf_["host"], conf_["port"])) body_ = {"analyzer": "kuromoji", "text": phrase} # runs one-time analyzer pprint(es.indices.analyze(body=body_)) def configure_index(): es = Elasticsearch("{}:{}".format(conf_["host"], conf_["port"])) if es.indices.exists(index=conf_["index"]): raise Exception("index already exists") body_ = _load_json("sample-conf.json") pprint(es.indices.create(index=conf_["index"], body=body_)) def push_doc(batch=False): # private sub function for iterable loading def _load_data(index_, type_): src_ = _load_json("data-source.json") for data_ in src_: yield {"_index": index_, "_type": type_, "_source": data_} es = Elasticsearch("{}:{}".format(conf_["host"], conf_["port"])) if not batch: for item in _load_data("myindex2", "docs"): pprint( es.index(index=item["_index"], doc_type=item["_type"], body=item["_source"])) else: pprint(helpers.bulk(es, _load_data("myindex3", "docs"))) def query_doc(): es = Elasticsearch("{}:{}".format(conf_["host"], conf_["port"])) # build query body_ = {"query": {"match": {"name": "ebisugawa"}}} pprint(es.search(index="myindex2", body=body_)) if __name__ == "__main__": try: if sys.argv[1] == "get": get_info() elif sys.argv[1] == "test": test_analyze("面白きことは良きことなり!") elif sys.argv[1] == "config": configure_index() elif sys.argv[1] == "send": push_doc() elif sys.argv[1] == "bulk": push_doc(batch=True) elif sys.argv[1] == "query": query_doc() else: raise Exception("unsupported argument") except: print_exc() |
おわり。