Elasticsearchの魅力の一つは豊富な機能。その分、使いこなすのが大変なので、少しでも実例ベースで勉強したいところです。素のWeb APIを使うこともできますが、Pythonにもサードパーティ製のクライアントが提供されています。
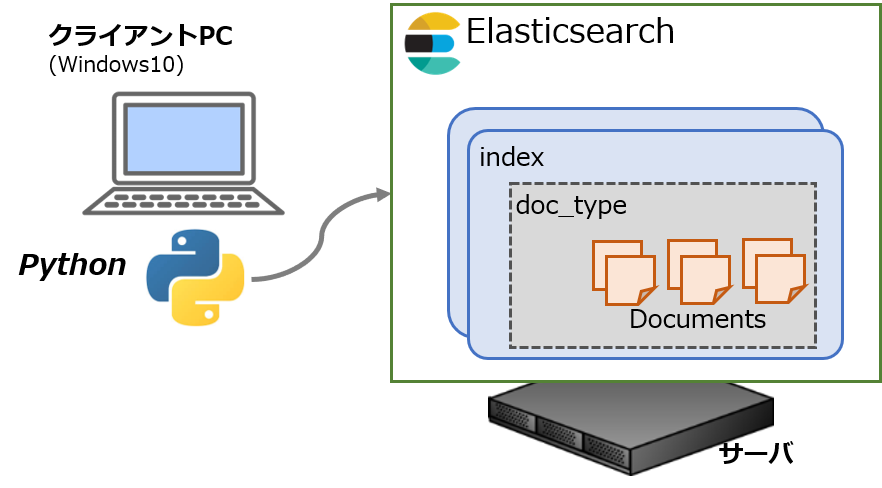
Pythonクライアント(elasticsearch-py: Python Elasticsearch Client)を使ったElasticsearchの操作についてメモしておきます。
もくじ:
Pythonクライアント
基本はElasticsearchクラスを使って操作していきます。
コンストラクタにはアクセス先となるElasticsearchサーバ側のホスト名(またはIPアドレス)を指定します。
1 2 3 4 5 6 7 | from elasticsearch import Elasticsearch from pprint import pprint conf_ = {"host": "eshost.local", "port": 9200, "index": "myindex1", "doc_type": "docs"} es = Elasticsearch("{}:{}".format(conf_["host"], conf_["port"])) |
プロトコルや複数のサーバを指定したりといった応用はありますが、基本は上記の形をおさえておけば大丈夫です。Elasticsearch本体とはJSON形式のWeb API(HTTP Rest)を使って通信しているようですが、Pythonオブジェクトとして扱えるようラップされています。
また、以下ではレスポンスを整形して表示させるためにpprintを使っています。
なお、今回は例を記載しませんが、標準のloggingモジュールを使ってクライアントのログを出力させることができます。DEBUGレベルのログを出すとWeb APIのペイロードまで表示して大量になってしまうので、必要に応じたログレベルの設定が欠かせませんが。
一対一の対応ではありませんが、Kibanaのコンソール「Dev Tools > Console」からもともとのAPIをコールすることができます。Elasticsearchアプリケーションのデベロッパーにはこちらのほうがお馴染みかもしれませんが、デバッグや設定確認に便利です。もちろんWeb APIとして整備されているのでcurlやその他HTTPリクエストを投げられるソフトウェアからもアクセスできます。
情報の取得
Elasticsearchの構築自体は別記事で、単体のセットアップ方法を記載しています。
Elasticsearchはスケールさせるためのクラスタ構成が前提となっており、単体で構築してもクラスタ名やノード名が自動的に設定されます。要件に応じてレプリカを別の冗長ノードにおいて信頼性を高めるなど、柔軟に構成できるようになっています。
手始めにノードの構成などサーバの情報を取得してみます。
1 2 3 4 5 6 | es = Elasticsearch("{}:{}".format(conf_["host"], conf_["port"])) pprint(es.info()) pprint(es.nodes.info()) pprint(es.indices.get(index="*")) pprint(es.indices.stats(index="*")) |
プラグインの情報はnodes API経由で取得することができます。
今回の構成では、日本語の字句解析のためKuromojiプラグインをインストールしているのでその様子がわかりますね。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | { "_nodes": {}, "cluster_name": "elasticsearch", "nodes": { "N...bdRbQ": { "name": "N...", ..., "plugins": [ { "name": "analysis-kuromoji", "version": "6.3.1", "elasticsearch_version": "6.3.1",... } ], ... } } } |
ちなみにWeb APIの場合は、以下でプラグインの構成を参照できます。Kibanaから実行させる場合や、curlコマンドを使う場合(サーバURLの指定が必要)に利用できます。
1 | GET /_nodes/plugins |
Elasticsearch().indicesプロパティを経由して、サーバに定義されているインデックスの構成や統計情報も取得することができます。例ではワイルドカードを使って全てのインデックスについて取得させています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | { ".kibana": { "aliases": {}, "mappings": { "doc": {...} }, "settings": {...} }, "myindex": { "aliases": {}, "mappings": {...}, "settings": {...} } } |
アナライザのテスト
全文検索の基本的な機能の一つは、字句(やデータ型)の比較により一致を判別すること、です。文章など長いデータから字句へうまく分割して記憶(インデキシング)しておけば検索の性能を高めることができるという寸法です。が、日本語についてはちょっと特殊な仕組みが必要になります。
文章がスペースで区切られていて、あとは活用形を考えればかなりの精度で正規化できる英語と違って、日本語の場合はまず文章から単語の区切りを判別する必要のある言語です。
単純に文字数で区切っていく方法(N-gram)もありますが、長い文章などは文法や品詞の辞書などの背景知識を使って分解(形態素解析)していくほうが処理量でも消費容量の面でも効果的な場面がありますので、さかんに開発されています。日本語の場合はKuromojiプラグインが有名ですね。
万能の方法はないので、データの素性に合わせて組み合わせを試し、設計していく必要があります。Elasticsearchの場合、より詳細にはトークナイザ(tokenizer)やフィルタ(filter)などよく考えられた仕組みが実装されていますので必要に応じて調べてみて下さい。
単純にKuromojiをアナライザに指定するだけでも、上手に字句を取り出すことができます。
1 2 3 4 5 6 | # 解析対象とする文章 phrase = "面白きことは良きことなり!" # kuromojiを指定して解析 body_ = {"analyzer": "kuromoji", "text": phrase} es = Elasticsearch("{}:{}".format(conf_["host"], conf_["port"])) pprint(es.indices.analyze(body=body_)) |
結果(レスポンス)はこんな感じ。キーワードが正規化されてトークン化されているのがわかりますね。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | { "tokens": [ { "token": "面白い", "start_offset": 0, "end_offset": 3, "type": "word", "position": 0 }, { "token": "良い", "start_offset": 6, "end_offset": 8, "type": "word", "position": 3 } ] } |
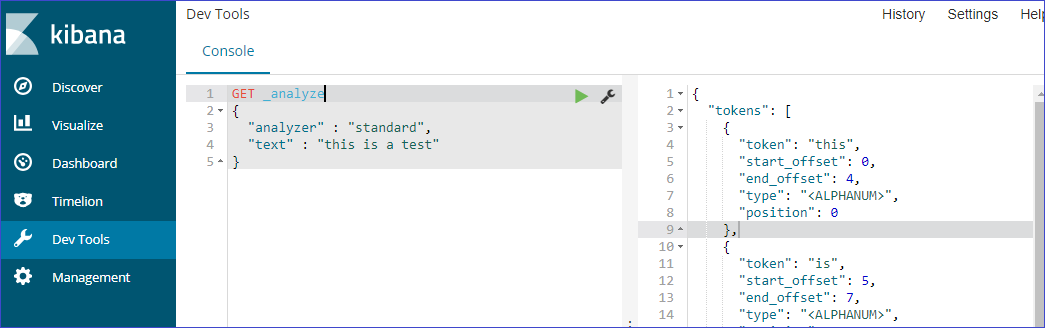
Web APIを使う場合も同様のフォーマットです。
1 2 3 4 5 | GET _analyze { "analyzer" : "standard", "text" : "this is a test" } |
インデックスの作成
データを投入する(ドキュメントをポストする)と、自動的にインデックスを新規作成し、マッピング(スキーマ)を自動で生成させることもできます。ただし、フィールド毎に細かく調整したいときなどマッピングをマニュアルで定義してインデックスを明示的に作成することができます。というより、ちゃんと使い方を設計する際にはむしろ手動で作成する場合が大半でしょう。
その他、トークナイザの設定など、インデックス毎の設定も同時に指定して作成できますし、別途テンプレートとして定義しておくこともできます。
設定を全て書くと階層が深くて長くなるので、別ファイル(JSON)に書いておいた設定を参照する場合の例を下記に示します。
1 2 3 4 5 6 | es = Elasticsearch("{}:{}".format(conf_["host"], conf_["port"])) if es.indices.exists(index=conf_["index"]): raise Exception("index already exists") body_ = _load_json("sample-conf.json") pprint(es.indices.create(index=conf_["index"], body=body_)) |
実際の設定について、マッピングのみを指定する例はこんな感じです。
mappingsキーの下にドキュメントタイプのキーがあり、さらにドキュメントのスキーマをプロパティ毎に列挙します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | { "mappings": { "docs": { "properties": { "tag": { "type": "keyword", "index": true }, "date_created": { "type": "date", "format": "yyyy/MM/dd HH:mm:ss||yyyy/MM/dd||epoch_millis" }, "subject": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "content": { "analyzer": "kuromoji", "type": "text", "fields": { "keyword": { "type": "keyword", } } } } } } } |
"tag"には完全一致させる文字列を想定し、"keyword"タイプのみを指定します。検索したい項目は{"index": true}と指定しますが、バイナリや他の項目と重複することがわかっている場合など検索が不要な項目についてはfalseを指定します。
"subject"のように部分一致も想定する場合には、"text"タイプや"keyword"タイプのフィールドを追加します。また、"content"の例のように日本語の文書が想定される場合に"kuromoji"をアナライザに指定します。文字列以外にも、数値"long"や、日付型"date"も定義することができます。
その他、インデックスさせない場合(検索対象にしない、バイナリなど)の指定方法などもあります。インデックスの設計によって、処理負荷や必要な記憶容量が変わってくるので、うまく設定したいものですね。
例によって長くなったので、データの投入と検索は別記事に回します。サンプルの全体像もそちらで。