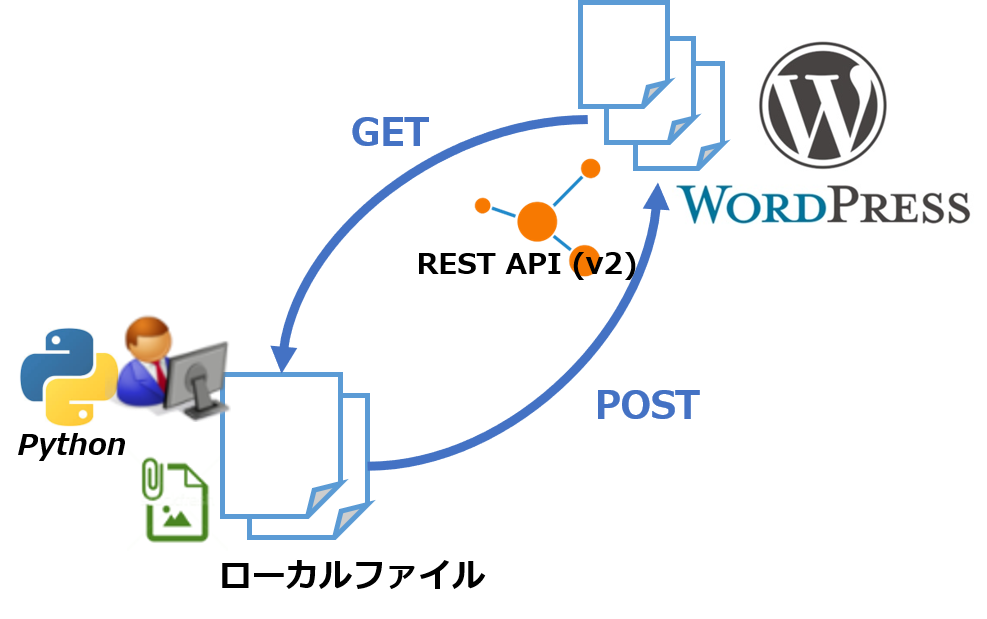
みんな大好きWordpressはCMS/ブログアプリケーションの有名な実装例、ですが、APIを使って管理できるとちょっとしたときに便利です。
CLIやエクスポートなど、豊富な機能がありますが、近頃REST APIはWordpressを設置するだけで使えるようになっています。
Pythonではrequestsモジュールを使うと簡単にREST APIを扱うことができるので、今回はその例をいろいろメモしておくことにしました。
検証した環境はWordPress 4.9.6(ja)、Windows 10 Pro、Python 3.6です。
もくじ:
事前準備
前提として、Wordpressはすでに設置済みと想定します。
WordPress側の設定
近頃のバージョン(4.7以降)ではデフォルトでREST APIが利用可能なようですが、それ以前のバージョンを利用している場合は別途プラグイン「WordPress REST API (Version 2)」のインストールが必要です。
また、サイトの運用者によっては、セキュリティ上の理由からREST APIを無効化するプラグインを導入している場合もあります。
変更を伴うAPIの実行には編集以上の権限を持つユーザを、認証を通した上で使用する必要があります。
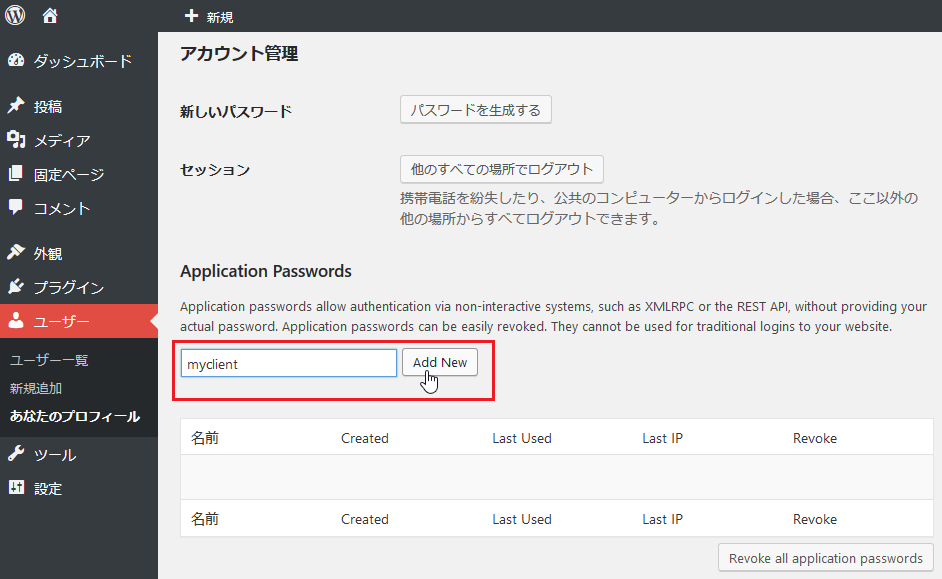
認証は基本的にはBasic認証。作成済のユーザのアカウントそのものを使うのが気になる場合は、専用のアプリケーションパスワードを発行させて利用終了時に破棄する手があります。
「Application Passwords」プラグインを使うと、ユーザの設定ページから発行することができます(パスワードは”AAAA BBBB CCCC DDDD”のような形式)。
Pythonモジュール
主にrequests、ところによりHTMLをパースするためにBeautifulSoupを使います。これでないとできないというわけではありませんが、おそらく最もシンプルに書ける部類の良いモジュールです。
インストールされていない場合はpipで導入できます。
1 2 | > pip install requests > pip install beautifulsoup4 |
エンコードはUTF-8に統一すると楽、ですが、Python 3系を使う場合はデフォルトでそうなっていると思いますので特に気にする必要はありません。
WordPressのREST API
ふつうのREST APIと同じく、基本形は”http(s)://(WordPressのドキュメントルート)/wp-json/wp/v2/(リソースのパス)”で、JSON形式のデータ(String)を各メソッドで送受信します。以降のPythonスクリプト中ではurllib.parseクラスを使って各リソースのパスを結合しています。
最近のサイトだとHTTPではなくHTTPSが多いと思われますが、APIも基本はそのサイトの設定に揃えます。
リソースは、よく使うものはこんな感じかと思います。
| URL | 説明 |
|---|---|
.../wp-json/wp/v2/posts | WordPressに作成された投稿 |
.../wp-json/wp/v2/users | 定義済みのユーザー |
.../wp-json/wp/v2/categories | 定義済みのカテゴリ |
.../wp-json/wp/v2/media | アップロードされたメディア |
他にもタグやコメント、固定ページといったWordpressユーザにはお馴染みのリソースが定義されています。.../posts/200のように下の階層にIDを指定すると個別のアイテムにアクセスすることができます。
APIのルート、この場合は”http://…/wp-json”または”http://…/wp-json/wp/v2″をGETするとAPIの一覧(JSON形式)が返ってきます。
参照(GETメソッド)系のAPIはブラウザでURLを開くだけで応答が確認できるので、動作確認は簡単です。もちろんcurlコマンドなどでも可。
ただし、作成・更新などの変更や設定(settings)の参照など、一部の操作にはWordpress側で設定したユーザの認証が必要になります。
また、URLが間違っている場合は素直に404が返ってくるケースがほとんど。REST APIが有効化されていて、APIのルート以下の階層で間違っている場合には404に加えてエラー内容のメッセージ(JSON)が応答されることもあります。
参照するのみであれば特に認証せずとも取得が可能です。
以下はrequestsモジュールを使って投稿(posts)を取得する例です。
# (APIの)”POSTメソッド”と”posts”(投稿)が似ていて非英語話者には紛らわしいですね
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | import requests from traceback import print_exc from urllib.parse import urljoin wp_base_url_ = "https://sample.wordpress.site.local/wp/" def get_posts_per_page(page_=1): # send request with specifying page number res = requests.get(urljoin(wp_base_url_, "wp-json/wp/v2/posts"), params={'page': page_}) return res.json() if __name__ == "__main__": try: get_posts_per_page(3) except: print_exc() |
といっても全ての投稿が取得できるわけではなく、基本は公開されているものがページネーションされて返ってきます。ページを指定するためにはクエリパラメータにページ番号(posts?page=...)を指定します。
レスポンスは.json()メソッドを使ってオブジェクト化していますので、あとはPythonの文法で値を取り出すことができます。
正常に取得できた場合、下記の例のように投稿がJSON形式のリストとして返ってきます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | [{ "id": 100, "date": "2017-01-14T17:00:00", "modified": "2018-02-01T22:38:38", "status": "publish", "type": "post", "link": "https://sample.wordpress.site.local/wp/archives/100", "title": { "rendered": "..." }, "content": { "rendered": "<p>...</p>\n",... }, "excerpt": { "rendered": "<p>...</p>\n",... "protected": false }, "author": 2, "categories": [3, 16,...], "tags": [], ... }, ...] |
キーを見ればおおよそ意味はつかめると思いますが、"id"が投稿のID、"status"が「下書き」や「公開」などの状態、"content"が本文です。"author"や"categories"などは生の文字列ではなく、サーバ側(WordPress)で内部的に振られたIDですね。
画像のダウンロード
標準で利用可能なエクスポート機能ではメディアが含まれないこともあり、投稿中に挿入した画像のダウンロードができると便利ですよね。
ここでは、上記の例で見たように投稿を取得、本文からimgタグを抽出、さらにタグのsrc属性(URL)を参照して画像データを取得する、というやり方にします。
投稿の書き方によってはsrcに画像の実体がセットされていないケースもありますが、まあ単純な方法としてはこれで十分でしょう。
上述のように、全投稿を一括で取得するような仕様にはなっていないので、事前に投稿IDを指定して対象を絞り込んでいます。
当たり前ですが、画像を多用しているようなサイトや大量のページをクロールする場合はトラフィックが大きくなりますので注意しましょう。他人様の個人サイトでやってはいけません。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | import os import requests from traceback import print_exc from bs4 import BeautifulSoup as bs from urllib.parse import urljoin wp_base_url_ = "https://sample.wordpress.site.local/wp/" def save_images(): post_id = [197, 198, 199, 170, 169, 168, 167, 166, 164, 165] # find picture source in img tag src_url = [] for item in post_id: # get specified post content url_ = urljoin(wp_base_url_, "wp-json/wp/v2/posts/{}".format(item)) print("retrieving post: {}".format(url_)) res = requests.get(url_) post_data = res.json() # parse source address in image tags soup = bs(post_data["content"]["rendered"], 'lxml') for img_tag in soup.find_all("img"): if img_tag["src"].startswith("http"): src_url.append(img_tag["src"]) else: src_url.append(urljoin(wp_base_url_, img_tag["src"])) # batch download for each url for item in src_url: try: # download from stream specified res = requests.get(item) local_path = os.path.basename(item) print("save image: {}".format(local_path)) with open(local_path, 'wb') as f: f.write(res.content) except: print("failed to save image: {}".format(item)) print_exc() continue if __name__ == "__main__": try: save_images() except: print_exc() |
BeautifulSoupはWebスクレイピングによく使われるモジュールですが、今回はimgタグを抽出するのに使っています。
その中で、srcにはアップロード先ディレクトリ内のリソースを指す相対パスが設定されている場合もありますが、静的コンテンツ用に別途CDNやクラウドストレージを利用している場合など、”http(s)://…”から始まるURL(絶対パス)がセットされている場合がありますので、相対パスの場合にはurljoinで絶対パスに変換しています。
ファイルを保存するところは、普通にリンク先を保存するのと同じようにrequestsモジュールを使います。バイナリのストリームとしてファイルに書き出せばそのまま画像ファイルとして保存することができます。面倒なのでリソース名をそのままファイル名に使っていますが、srcにクエリ文字列が含まれている場合など処理系によってファイルシステムに使えない名前になってしまう場合は保存に失敗します。
画像のアップロード
ダウンロードとは逆に、POSTを使ってメディアをアップロードすることができます。
Wordpress標準のメディアアップロードページでも複数ファイルを指定することができますが、数十、数百個となるとうまく動かないケースが多いので、そんなときはPythonにやらせましょう。
アップロードの操作はWordpress上のデータに変更を加えることになるので、設定済みのアカウントを使った認証が必要になります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | import os import requests from traceback import print_exc from urllib.parse import urljoin wp_base_url_ = "https://sample.wordpress.site.local/wp/" def upload_image(image_file_path): # check local file path if not os.path.isfile(image_file_path): raise Exception("invalid file path: {}".format(image_file_path)) # credential user_ = "wpuser" pass_ = "xxxx xxxx xxxx xxxx" # build header file_name = os.path.basename(image_file_path) headers_ = { "Content-Disposition": 'attachment; filename="{}"'.format(file_name), "Content-Type": "application/octet-stream"} # read local picture file with open(image_file_path, 'rb') as f: img_data = f.read() # send POST request res = requests.post(urljoin(wp_base_url_, "wp-json/wp/v2/media/"), data=img_data, headers=headers_, auth=(user_, pass_)) print(repr(res)) if __name__ == "__main__": try: upload_image("C:\\path\\to\\myimage.jpg") except: print_exc() |
user_、pass_にはWordpressで設定済のものを代入します。requestsのauth引数にタプルとして渡すとBasic認証(Base64エンコード)のヘッダを作ってくれるので便利ですね。
画像ファイルをバイナリモードで読み、POSTリクエストのボディとして渡します。APIのバージョンによって微妙に振る舞いが異なるようですが、Content-typeに”application/octet-stream”を明示的にセットするとうまくいくようです。画像ファイルはスクリプト内で(ローカルの)絶対パスまたはスクリプト実行場所からの相対パスで指定し、ファイル名をアップロード対象の画像リソース名に使っています。
同期的にPOSTリクエストを送信し、アップロードがうまくいけば成功の応答(HTTPステータス200)が返ってきます。アカウントの設定が間違っているなど認証が通っていなければpermission deniedやunauthorizedが返ってくるでしょう。
新しい投稿の作成
新しい投稿を作成するには、JSON形式の本文をPOSTすれば最低限はOK。指定しなかった他のパラメータにはデフォルト値が適用されます。
さらに定義済のカテゴリやユーザを指定する場合には、各々のIDを渡す必要がありますので事前に取得しておくと良いでしょう。
下記の例のように、ユーザは.../usersにGETリクエストを送った場合のレスポンス(JSON形式のリスト)として、
1 2 3 4 5 | [{ "id": 2, "name": "wpuser", ... },...] |
同じくカテゴリは.../categoriesのレスポンスとして取得することができます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | [{ "id": 3, "count": 1, ... "name": "カテゴリ1", "taxonomy": "category", "parent": 0, ... }, { "id": 9, "count": 1, ..., "name": "サブカテゴリ1-2", "taxonomy": "category", "parent": 3, ... }, { "id": 12, "count": 10, ..., "name": "サブカテゴリ1-2", "taxonomy": "category", "parent": 3, ... },...] |
下記は投稿を作成する例です。
APIの認証を通すユーザ(user_)と、投稿自体の作成者(user_id)は同一でなくても構いませんが、もちろんWordpress側で設定済みである必要があります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | import json import requests from traceback import print_exc from urllib.parse import urljoin from datetime import datetime wp_base_url_ = "https://sample.wordpress.site.local/wp/" def create_post(title_, content_): # credential and attributes user_ = "wpuser" user_id = 2 category_ids = [10] pass_ = "xxxx xxxx xxxx xxxx" # build request body payload = {"title": title_, "content": content_, "author": user_id, "date": datetime.now().isoformat(), "categories": category_ids, "status": "draft"} # send POST request res = requests.post(urljoin(wp_base_url_, "wp-json/wp/v2/posts"), data=json.dumps(payload), headers={'Content-type': "application/json"}, auth=(user_, pass_)) print(repr(res)) if __name__ == "__main__": try: create_post("post via api", "text body of example post") except: print_exc() |
送信するデータ(リクエストボディ)はJSON形式の文字列にエンコードする必要があります。
投稿の作成者やカテゴリは上述のIDを使い、カテゴリやタグなど複数指定が可能なものはリストとして渡します。また、"status"を"draft"にしておくと下書き状態で登録されます。
通常GUIから投稿した場合と同じく、投稿自体のIDやその他の値はWordpress側で採番されます。
おわり。