MongoDBはスキーマ定義が柔軟なドキュメント指向のデータベース。JSONっぽいデータ形式で何でも突っ込んでおけますし、最低限ならそこまでハードの要求も高くないので手軽に使いやすいですね。
もくじ:
はじめに
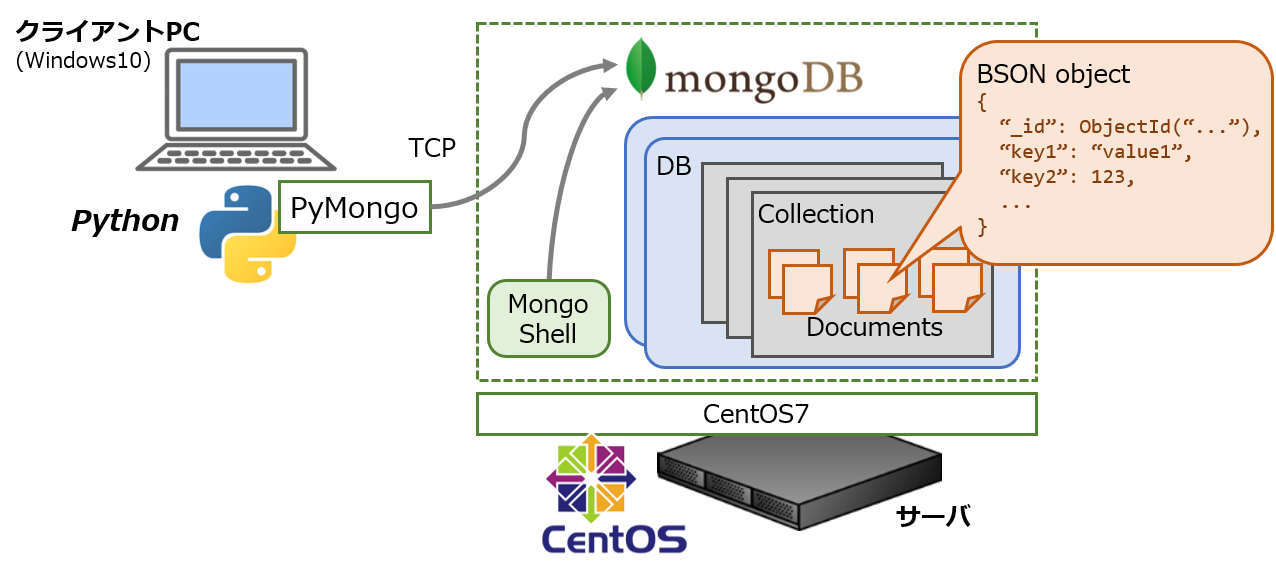
今回はセットアップ方法と簡単な使い方について記載します。リモートからアクセスできるようにしたいので、MongoDBのエコシステムが提供しているクライアント(native driver)を使います。
以前のバージョンではRest APIが叩けましたが、最近ではサポートしていないんですね。セキュリティ上の理由でしょうか。あるいはStitchを使えってことでしょうかね。
ということでここではPython用のクライアント(pymongo)を使います。
今回はCentOS7にMongoDB 4.0をyum経由でインストールしました。クライアントはWindows10 Pro + Python 3.6です。インストール方法の基本はLinuxの主要なディストリビューションなど公式マニュアルに豊富な記載があります。
MongoDBのセットアップ
CentOS7マシン上でMongoDB(サーバ側)を構成していきます。
rootで作業していますが、他のユーザを使用する場合はもちろんsudoで昇格するなどが必要です。
インストール
MongoDB 4.0 (Community Edition)を指すyumレポジトリを設定します。
基本的に形式が統一されているので、バージョン番号の部分を変更すれば他のバージョン(3.4, 3.6など)をインストールできるようになっています。
1 2 3 4 5 6 7 8 | $ vi /etc/yum.repos.d/mongodb-org-4.0.repo # 以下の内容で作成 [mongodb-org-4.0] name=MongoDB Repository baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.0/x86_64/ gpgcheck=1 enabled=1 gpgkey=https://www.mongodb.org/static/pgp/server-4.0.asc |
あとはyumでインストールするだけです。
1 | $ yum install -y mongodb-org |
無事にインストールが成功した暁にはサービスとして登録されますので、systemctlで立ち上げるか、あるいは自動起動が設定されているのでマシンを再起動しても立ち上げることができます。
1 | $ systemctl start mongod |
公式のマニュアルにはSELinuxを設定せよ(Disableするか許可の設定を書くか、など)と書いてありますが、私の試した限りでは不要でした(デフォルトのEnableされたままの状態)。
ファイヤウォール・外部アクセスの設定
サーバと同じマシンでMongoDBを利用するケースでは問題ありませんが、クライアントとサーバを別のマシンで動かす際には追加で設定が必要になります。
ファイヤウォール(firewalld)を利用していて、外部からアクセスさせたい場合はポートを開けておきます。もちろんファイヤウォールが不要な場合はスキップできます。
設定例ではMongoDBのデフォルトの27017番を想定していますが、変更している場合は設定に応じて読み替えて下さい。
1 2 3 4 5 6 7 8 | # インストールされていない場合 $ yum install -y firewalld $ systemctl enable firewalld # 起動されていない場合 $ systemctl start firewalld # ポート設定(デフォルトゾーンの場合) $ firewall-cmd --permanent --add-port=27017/tcp $ firewall-cmd --reload |
また、デフォルトの設定ではローカルホストのみ接続が許可されているので、他のマシンからアクセスさせたい場合はbindIpの設定変更が必要です。
デーモンの設定ファイル/etc/mongod.conf (YAML形式)内で、bindIpの項目を”0.0.0.0″に変更すると、任意のアドレスからアクセスを受け付けるようになります。
そのままではセキュリティ上よろしくないので、ふつうは認証(security-authorizationの項目)を有効化し、データベースにアカウントやアクセス権限を定義します。が、ここでは説明を割愛します。
1 2 3 4 5 6 7 8 9 | # mongod.conf ... # network interfaces net: port: 27017 bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses ... #security: # authorization: enabled |
変更した設定は、デーモンの再起動などで反映されます。
設定の確認
セットアップの作業自体は上記までで大丈夫なはずですが、何かうまくいっていない場合や動作確認には以下を確認して下さい。
ログは/var/log/mongodb/mongod.logに記録されます。
うまく起動されている場合は、設定したポート番号でListenしている旨のメッセージが記録されているはず。
1 2 3 4 | $ tail /var/log/mongodb/mongod.log ... ... [initandlisten] waiting for connections on port 27017 ... |
サーバ側のマシンではmongoコマンドでシェルに入ることができます。初期設定や基本的なトラシューはこのシェルが便利。
シェル起動時には構成上の警告などの情報も表示されます。
公式にも解説がありますがJavaScriptっぽい構文です。仕様はバージョン毎に微妙に違う場合もありますが、文法を間違えている場合などエラーを出してくれることもあります。
統計情報の表示や、ユーザアカウントの作成といった操作で使うと便利ですかね。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | $ mongo MongoDB shell version v4.0.0 connecting to: mongodb://127.0.0.1:27017 MongoDB server version: 4.0.0 Welcome to the MongoDB shell. ... # データベース一覧の表示 > show dbs admin 0.000GB config 0.000GB local 0.000GB testdb 0.001GB # 対象のデータベースを切り替え(存在しなければ作成) > use testdb # 統計情報の表示 > db.stats() # ユーザの作成 > db.createUser({user: "username", pwd: "password", roles: [{role: "readWrite", db: "testdb"}]}) Successfully added user: { "user" : "username", "roles" : [{ "role" : "readWrite", "db" : "testdb" }] } # ユーザ設定の確認 > use admin switched to db admin > db.system.users.find() { "_id" : "testdb.username", "user" : "username", "db" : "testdb", "credentials" : ... > exit |
ここまででサーバ側のセットアップは一旦完了です。
PyMongoでのアクセス
以降はクライアント側での作業です。
上にも書きましたがMongoDB 3.6あたりからWeb API (Rest API, http://…)が使えなくなっていますので、native driver (mongo://…)でアクセスする必要があります。まあ普通はサードパーティ製のクライアントを使うので特に意識しないと思いますが。。。
Pythonの場合はpymongoモジュールの完成度が高く、よく利用されるようです。
今回はサンプルとして、クライアント側マシンのファイル情報をデータベースに格納する、というスクリプトを作成しました。検索の例として、ファイルの内容を検証する機能も付けることにします。スクリプトの全体像は後ほど記載します。
セットアップ
例によってpipでインストールできます。
1 | > pip install pymongo |
基本的にはMongoClientクラスを利用してデータベースにアクセスします。
1 2 | from pymongo import MongoClient _client = MongoClient(...) |
MongoClientのコンストラクタには、サーバの指定に必要な情報、ホスト名(IPアドレスでも可)などを指定します。以降の例はホスト名とポート番号(TCP)を使用しています。他にもconnection string (mongo://…)を指定することもできます。
DB統計の取得
RDBMSでいうと、db(database)がインスタンス、collectionがテーブル、各ドキュメントがテーブル内のレコード本体に相当します。
dbは複数のcollectionを持つことができ、スキーマ定義(カラム定義)はcollectionのレベルで操作します。
pymongoでは、これらの階層をプロパティのようにMongoClient().db_name.collec_nameの形か、あるいはdictオブジェクトのようにMongoClient()[db_name][collec_name]の形式で書いてアクセスすることができます。
以下の.command()メソッドを使うことで、データベースのレベルでの操作が可能です。下記のようにするとmongoシェルと同じく、名称や作成済のドキュメント数('objects')など、データベースのレベルの統計情報を取得することができます。
1 2 3 | def get_stat(): _db = MongoClient(host=conf_["host"], port=conf_["port"])[conf_["database"]] pprint(_db.command("dbstats")) |
結果(Pythonオブジェクト)はこんな感じになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 | {'avgObjSize': 261.0137888198758, 'collections': 1, 'dataSize': 2101161.0, 'db': 'testdb', 'fsTotalSize': 75125227520.0, 'fsUsedSize': 1849749504.0, 'indexSize': 81920.0, 'indexes': 1, 'numExtents': 0, 'objects': 8050, 'ok': 1.0, 'storageSize': 937984.0, 'views': 0} |
データの投入
データをデータベースに投入するには、collectionに対してインサートします。特別に指定しない場合、ユニークなIDがサーバ側で自動的に生成されますので、後の処理で参照させるために知りたい場合はメソッドの返り値として取得することもできます。
単一のデータを投入するには.insert_one()メソッドにオブジェクトを渡せば十分です。
1 2 3 | _col = MongoClient(host=conf_["host"], port=conf_["port"])[ conf_["database"]][conf_["collection"]] id_ = _col.insert_one(info_).inserted_id |
よくあるJSON型のドキュメント指向データベースと違って、MongoDBは日付型などサポートしている型が豊富です。例えばPythonの場合、datetime型などをいちいち文字列に変換・パースする必要がないなど、扱いやすい作りになっています。
Pythonでバッチ処理させるようなケースではこちらが大半だと思いますが、同じような形式の複数ドキュメントを一括で投入する場合にはbulkインサート(.insert_many()メソッド)が使えます。メソッドにはリストを渡します。
1 2 3 | _col = MongoClient(host=conf_["host"], port=conf_["port"])[ conf_["database"]][conf_["collection"]] _col.insert_many(info_buf) |
ちなみに、インサートに失敗した場合(IDが重複していた、など)は例外を出しますので、特にキャッチしなければbulkインサートの途中で処理が止まります。
検索
クエリの例を説明するために、MongoDBの使い方そのものとは関係ありませんが、今回は同じ内容をもつファイルを検索させる機能を作成することにします。といっても、内容全てではなくハッシュ値を計算して一致するものを検索するので、別の内容でも偶然に衝突してしまう可能性は排除できませんが。。。
つまり同じファイル名やタイムスタンプの違いに関わらず、同じ内容(同じハッシュ値)のものを見つけることができるはずですね。
データベースに格納済みのドキュメントを検索するには、collectionに対して.find()メソッドを使います。メソッドにハッシュ値('digest'キー)を指定することで、ファイルの内容を渡します。この場合、結果は複数見つかる可能性がありますが、返り値はリストではなくイテレータのようなもの(cursor)になるので、今回は長さを取得するため一旦リストにキャストしています。
1 2 3 4 5 6 7 8 | def check_duplicated_content(): _col = MongoClient(host=conf_["host"], port=conf_["port"])[ conf_["database"]][conf_["collection"]] ... for item in _list_files(conf_["local_dir"]): info_ = _get_file_info(item) res = list(_col.find({"digest": info_["digest"]})) ... |
もちろんイテレータ的に使うならキャストする必要はありません。
.find()メソッドについては、複数のキーを指定したり、結果をソートするなど他にも使い方があります。
インデックスの作成
RDBMSと同じく、インデックスを張ることで検索速度を高めることができます。
pymongoでは、.create_index()メソッドにフィールド名を指定することでインデックスを作成させます。
1 2 3 | def set_index(): client_ = MongoClient(host=conf_["host"], port=conf_["port"]) client_[conf_["database"]][conf_["collection"]].create_index("digest") |
MongoDBのインデックスにもいくつか種類がありますが、今回の例ではシングルフィールド(昇順)かつ重複可のインデックスが作成されます。
同じくファイル内容を列挙して検索させる処理時間を、インデックス作成の前後で比較してみると、下記のような結果になりました。
1 2 3 4 5 6 7 8 | # インデックス作成前 > python sample.py check erapsed time: 28.52[sec] # 'digest'でインデックス作成 > python sample.py set # インデックス作成後 > python sample.py check erapsed time: 10.94[sec] |
DBにクエリをかけている時間よりもファイルシステムをスキャンしている時間の方が長いので、DBアクセスがボトルネックというわけではないのですが。まあご参考までに。
今回は8,000件程度の検索なので、かなり規模は小さいですが、件数やレコードそのものが大きくなるにつれインデックスが重要になる点はSQLと同じですね。投入するデータの素性やアプリケーションの目的がはっきりしている場合は、このあたりの設計が重要になるでしょう。
サンプル
以下が今回のサンプルです。上で説明した各項目を関数として定義し、スクリプト実行時の引数によって操作を分岐(__main__に記載)させています。
1 2 | # 例)DB統計の取得 > python sample.py stat |
MongoClientに設定する項目はひとまとめにdistオブジェクト(conf_)として定義してあるので、構成に合わせて変更が必要です。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 | import sys import os import hashlib from traceback import print_exc from pprint import pprint from pymongo import MongoClient conf_ = {"host": "mgdb.local", "port": 27017, "database": "testdb", "collection": "docs", "local_dir": "C:\\pathto\\documents"} def _list_files(dir_path): result = [] for path_, dirs_, files_ in os.walk(dir_path): dirs_[:] = [x for x in dirs_ if '.git' not in os.path.join(path_, x)] for file_name in files_: result.append(os.path.join(path_, file_name)) return result def _get_file_info(path_): # calculate SHA1 digest _hash = hashlib.sha1() _bsize = 4096 * _hash.block_size with open(path_, 'rb') as f: while True: _chunk = f.read(_bsize) if len(_chunk) == 0: break _hash.update(_chunk) # build file info return {"name": os.path.basename(path_), "path": os.path.normpath(path_), "size": os.path.getsize(path_), "date": {"modified": os.path.getmtime(path_), "created": os.path.getctime(path_)}, "digest": _hash.hexdigest()} def get_stat(): _db = MongoClient(host=conf_["host"], port=conf_["port"])[ conf_["database"]] pprint(_db.command("dbstats")) def check_duplicated_content(): _col = MongoClient(host=conf_["host"], port=conf_["port"])[ conf_["database"]][conf_["collection"]] duplicates_ = [] for item in _list_files(conf_["local_dir"]): info_ = _get_file_info(item) res = list(_col.find({"digest": info_["digest"]})) if len(res) > 1: buf_ = [x["path"] for x in res] buf_.sort() if buf_ not in duplicates_: duplicates_.append(buf_) for item in duplicates_: pprint(item) def send_data(): # bulk insert info_buf = [_get_file_info(x) for x in _list_files(conf_["local_dir"])] _col = MongoClient(host=conf_["host"], port=conf_["port"])[ conf_["database"]][conf_["collection"]] _col.insert_many(info_buf) def set_index(): client_ = MongoClient(host=conf_["host"], port=conf_["port"]) client_[conf_["database"]][conf_["collection"]].create_index("digest") if __name__ == "__main__": try: if sys.argv[1] == "stat": get_stat() elif sys.argv[1] == "send": send_data() elif sys.argv[1] == "set": set_index() elif sys.argv[1] == "check": check_duplicated_content() else: raise Exception("unsupported") except: print_exc() |
おわり。