Elasticsearchは全文検索エンジン。
AWSやelastic社のクラウドサービスもありますが、インターネットへの接続に制約がある場合など、ローカルの環境に構築することもできます。
もくじ:
はじめに
よく使っていた環境ではElasticsearch 5.xで構築していたのですが、最近Elasticsearch 6.xを使うケースがあり、そのときの導入手順をメモしておきます。
といっても基本的には5.x系と手順はそう変わっていません。
CentOSでのざっくりとした構築手順と、Pythonでの簡単な接続テストについても記載しておきます。
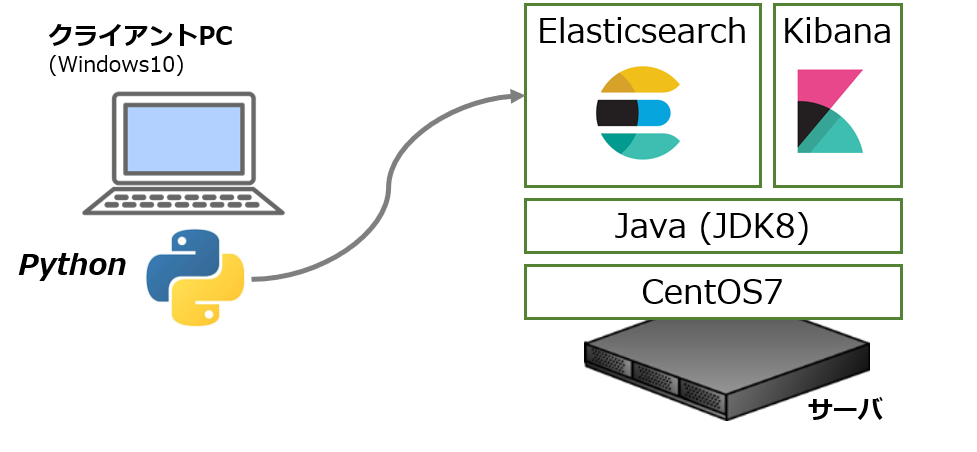
今回の環境はサーバ側がCentOS7, Elasticsearch 6、クライアント側がWindows 10 Pro, Python 3.6です。
認証付きプロキシありの環境では先に環境変数http_proxyを設定しておくと便利です。
1 2 3 | $ proxy_url="http://{PROXY_USER}:{PROXY_PASSWORD}@{PROXY_ADDRESS}:{PROXY_PORT}/" $ export http_proxy=$proxy_url $ export https_proxy=$proxy_url |
今回はrootで作業していますが、他のユーザで作業する場合には環境に合わせてsudoを使って下さい。
Elasticsearchのインストール
ここではyumを使ってインストールしていきます。インストールのみならず、のちのちアップデートする際もyumを使えるので便利です。
yum経由のインストール
前提となるJavaをインストールします。8以上が必須らしいです。
1 2 | $ yum install -y java-1.8.0-openjdk-devel $ java -version |
レポジトリに追加します。下記は6.x系の例ですが、5.xに置換すれば5.xが入るはず。
1 2 3 4 5 6 7 8 9 10 11 | $ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch $ vi /etc/yum.repos.d/elasticsearch.repo # 下記を入力して保存 [elasticsearch-6.x] name=Elasticsearch repository for 6.x packages baseurl=https://artifacts.elastic.co/packages/6.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md |
あとはいつものコマンドでインストールできるはず。
1 | $ yum install elasticsearch |
設定ファイルの編集
デフォルトではローカルアドレスのみアクセスが許可されていますので、他のマシンから参照できるように設定ファイルを編集します。
/etc/elasicsearch以下の設定ファイル(YAML)には設定項目がコメントアウトされているので、必要な項目のコメントを削除して有効化します。
1 2 | $ vi /etc/elasticsearch/elasticsearch.yml network.host: [_site_, _local_] |
上の例ではローカルホストと、同一ネットワークのアクセスを許可しています。"0.0.0.0"にすると任意のアドレスからアクセスできるようになりますが、セキュリティ上は慎重に使ったほうがいいですね。
変更を反映するにはサービスの再起動が必要なので、すでに起動している場合は注意して下さい。
ファイヤウォールの設定
ファイヤウォールを利用している場合はElasticsearch用にポートを許可しておきます。デフォルトでは9200, 9300ですが、上記の設定ファイルで変更している場合はそれに合わせて指定して下さい。
1 2 3 | $ firewall-cmd --zone=public --add-port=9200/tcp --permanent $ firewall-cmd --zone=public --add-port=9300/tcp --permanent $ systemctl restart firewalld.service |
サービスの設定
systemctlでサービスの開始・停止の操作、自動起動の設定を制御できます。
1 2 | $ systemctl enable elasticsearch $ systemctl start elasticsearch |
うまく起動していれば、ブラウザやcurlなどで接続した場合に設定(JSON形式)を応答してきます。
1 2 3 4 5 6 7 8 9 10 11 | $ curl http://localhost:9200/ { "name" : "...", "cluster_name" : "elasticsearch", "cluster_uuid" : "...", "version" : { "number" : "6.2.3", ... "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" } |
プラグインのインストール
字句解析用のアナライザなど、付加的な機能はプラグインとして導入することができます。
構成管理用のCLI(binディレクトリにあるスクリプト)を使ってインストールします。
サービス設定から調べると、/usr/share/elasicsearchにインストールされているようなので、binディレクトリのスクリプトを指定して任意のプラグインをインストールします。
下記は日本語の字句解析を行うためのkuromojiプラグインをインストールする例です。
1 2 | $ cd /usr/share/elasticsearch $ bin/elasticsearch-plugin install analysis-kuromoji |
基本はネットワークインストールなのですが、プロキシの内側でインストールする場合には内部的に動作しているJavaの環境変数(オプション)にhttp/httpsプロキシを設定する必要があります。
1 | $ ES_JAVA_OPTS="-Dhttp.proxyHost={PROXY_ADDRESS} -Dhttp.proxyPort={PROXY_PORT} -Dhttps.proxyHost={PROXY_ADDRESS} -Dhttps.proxyPort={PROXY_PORT}" bin/elasticsearch-plugin install analysis-kuromoji |
が、認証付きプロキシではこの方法がうまくいかなかったので、curlでダウンロードしたのちファイルからオフラインインストールする、という二段構えにしました。下記は上記と同じくkuromojiをインストールする例です。
プラグインのオフラインインストール用ファイルのURLはたぶんググれば出てきますが、対象のElasticsearchと互換のバージョンを使って下さい。
1 2 3 4 5 6 | $ cd ~ $ mkdir es $ cd es $ curl -O https://artifacts.elastic.co/downloads/elasticsearch-plugins/analysis-kuromoji/analysis-kuromoji-6.2.3.zip $ cd /usr/share/elasticsearch $ bin/elasticsearch-plugin install file:///root/es/analysis-kuromoji-6.2.3.zip |
構文は見たまんまなのですが、プラグイン名の代わりにダウンロードしたzipファイルの場所を指定しています。zipファイルの場所は環境に合わせて好きな場所に変更して下さい。
今回はrootアカウントを使っているので、esという名前のディレクトリをホームディレクトリ以下に作成してそこに置いています。もちろんインストールが終わればzipファイル自体は削除して大丈夫です。
Pythonでの接続テスト
PythonではElasticsearchのREST APIをラップしたモジュールが提供されているのでこれを使います。いつもの通りpipでインストール可能です。
1 | $ pip install elasticsearch |
バージョンはElasticsearchのメジャーバージョンと対応しており、基本的には後方互換性があります。現時点では6系が最新なので、Elasticsearch 5, 6系を使うぶんには特にバージョンを指定しなくてもいけるはず。
ちなみにElastic社は関連のソフトウェアスタックをスイート化し、バージョニングを統一した経緯があり、Elasticsearchのバージョンは2から5に飛んでいます。
設定の取得
単純な操作はElasticsearchクラスを呼べば充分です。
動作確認がてら、一般的な設定を取得してみましょう。下記のようにするとブラウザでトップ(ドキュメントルート)にアクセスした場合と同等の情報を取得することができます。
1 2 3 4 | from elasicsearch import Elasticsearch es = Elasticsearch("{SERVER_ADDRESS}:9200") print(repr(es.info())) |
elasicsearch.Elasticsearch()クラスのシンプルな例では、サーバのアドレスを渡して初期化します。
結果はこんな感じのオブジェクト(整形してあります)になります。
1 2 3 4 5 6 7 8 9 10 | { "name": "...", "cluster_name": "elasticsearch", "cluster_uuid": "...", "version": { "number": "6.2.3", ... "minimum_index_compatibility_version": "5.0.0" }, "tagline": "You Know, for Search" } |
インデックスの作成
実際にデータを投入してみるには下記のようにします。
指定したインデックスindexやdoc_typeが存在しない場合には自動的に作成されます。また、ここではbodyにデータ(ドキュメント)となるJSON文字列を渡していますが、マッピング(いわゆるスキーマ)もこのデータに合わせて自動的に定義されます。もちろんマッピングをちゃんと設定するAPIもあります。
1 2 3 4 5 6 7 | import json from datetime import datetime from elasicsearch import Elasticsearch sample_data = {"metrics1": "strmetrics", "metrics2": 2001, "metrics3": datetime.now().isoformat()} es = Elasticsearch("{SERVER_ADDRESS}:9200") result = es.index(index="testindex", doc_type="testdoctype", body=json.dumps(sample_data)) |
Kibanaのインストール
Kibanaは専らElasticsearch用のGUIです。必須ではありませんが、検索や設定変更などちょっとした操作から、ダッシュボードの作成まで、だいたいのことができてしまうのでインストールしておくと楽です。
今回はElasticsearchと同じサーバにセットアップします。
yum経由のインストール
レポジトリの設定はElasticsearchと共通。同じホストにインストールする場合はそのままyumでインストールできます。
逆にElasticsearchと別のホストにインストールする場合は、Javaやレポジトリ設定など前提条件の設定を別途行う必要があります。
1 | $ yum install kibana |
設定ファイルの編集
Elasticsearchの場合と同様にアクセス元のアドレスを指定しておきます。
1 2 | $ vi /etc/kibana/kibana.yml server.host: 0.0.0.0 |
先と同じく、変更を反映するにはサービスの再起動が必要です。
ファイヤウォールの設定
Kibanaの場合はデフォルトが5601番ポートになっていますので必要に応じて許可しておきます。
1 | $ firewall-cmd --zone=public --add-port=5601/tcp --permanent |
サービスの設定
これもElasticsearchの場合と同様です。
1 2 | $ systemctl enable kibana $ systemctl start kibana |
テスト
うまく設定できていれば、Web UIが立ち上がっているはずです。すでにElasticsearch側にデータが投入されている場合には、検索をかけたりすることもできます。
ブラウザでサーバの5601番ポート(デフォルトの場合)にアクセスします。
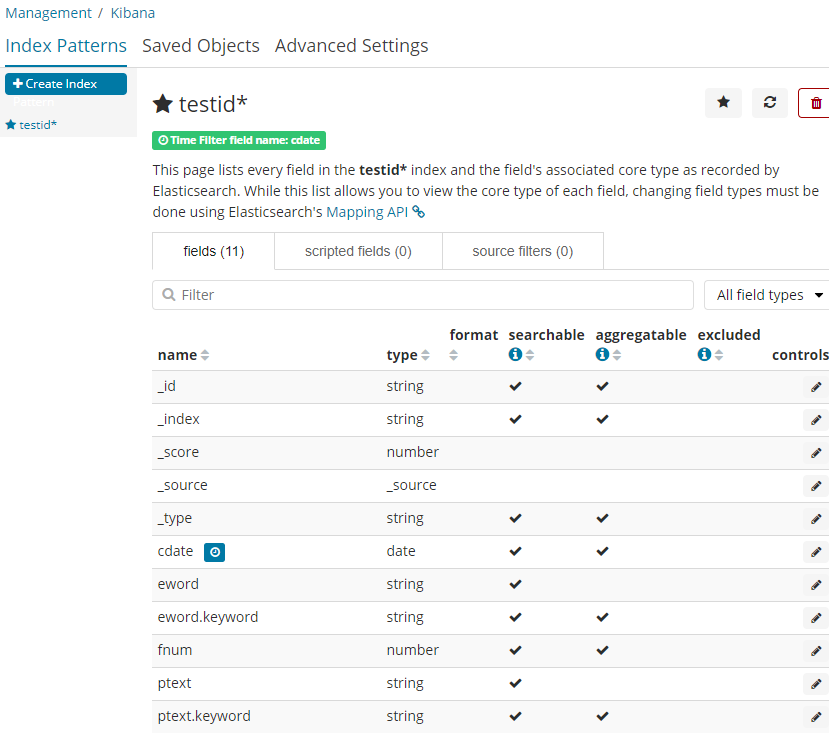
手始めにインデックスパターンを作成しておきます。
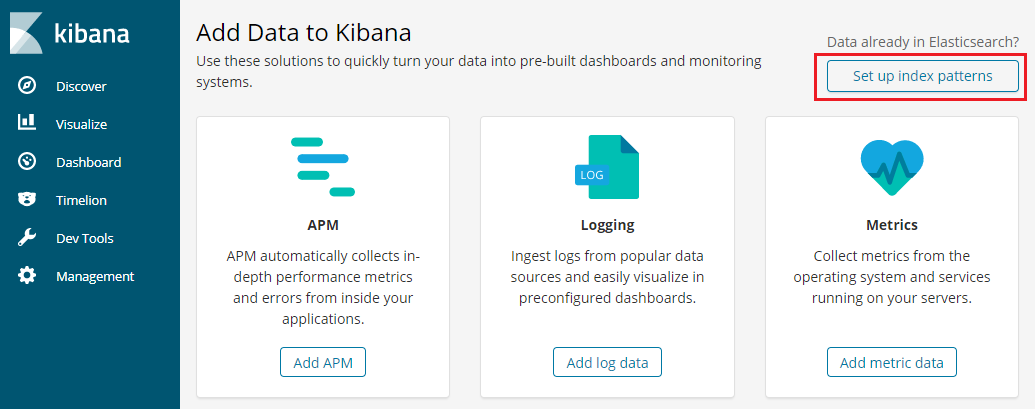
投入しておいたインデックスを指定。
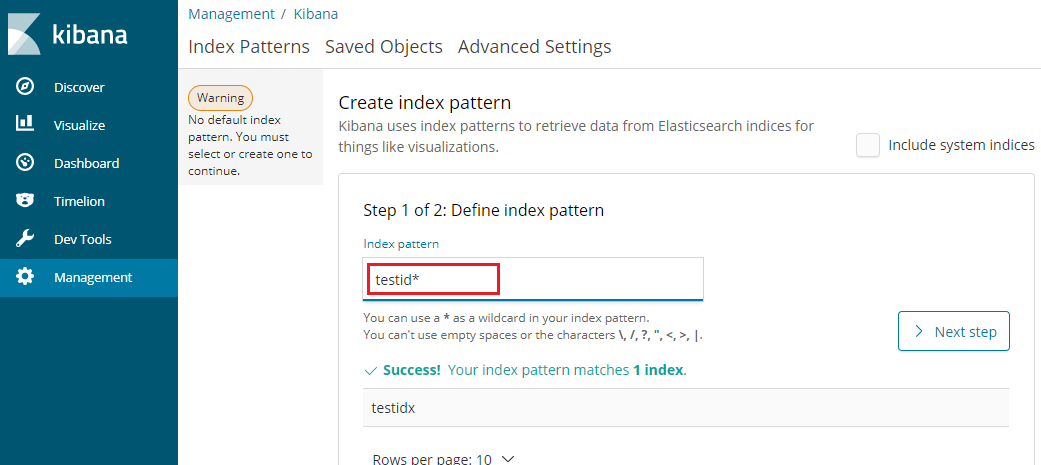
例えば時刻データのフィールドがある場合はTime filterを指定できます。
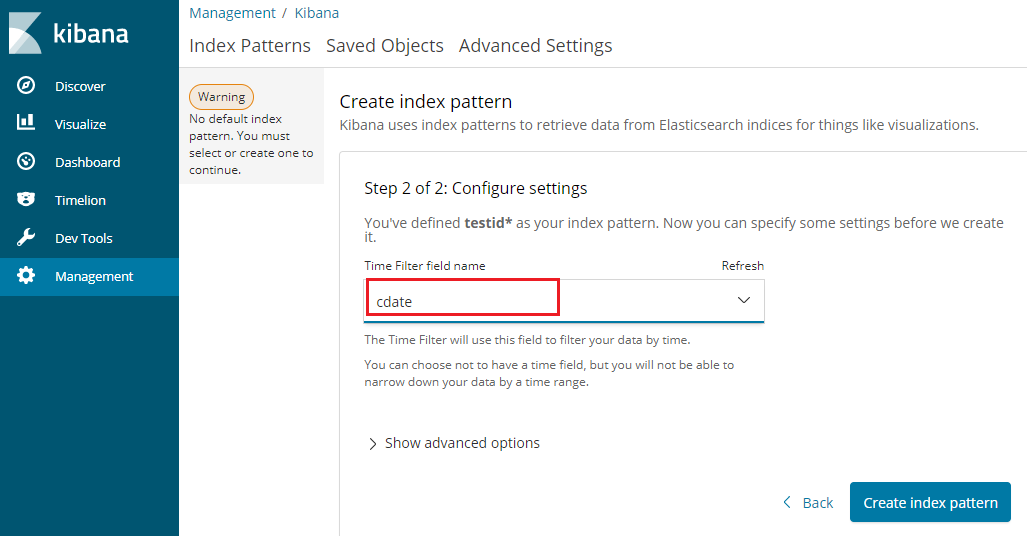
サーバ側で自動的に型を解釈してくれていますね。
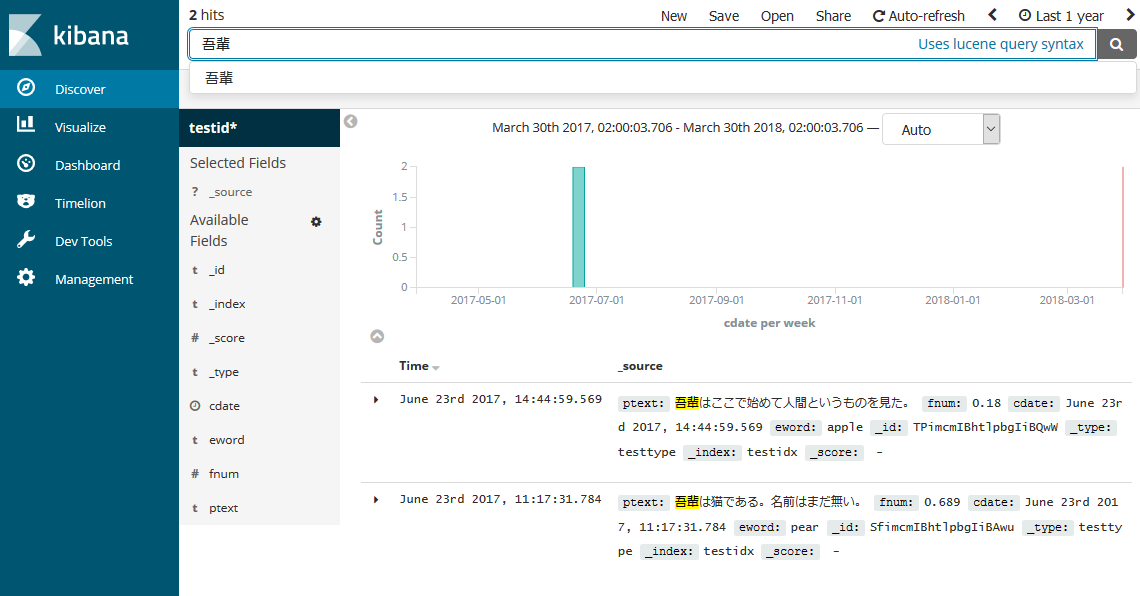
Discoverタブから検索できます。
おわり。