別記事の続きです。
Azure Storageは従量課金なので、できるだけ通信量や消費容量を削減したいですね。Azure側でのレプリケーション設定(冗長設定)も地味に差が出ますが、アップロード・ダウンロードに気を付けたいところ。
今回は通信量&消費容量を削減するため、Zipで圧縮して転送することにします。
そもそも何等かの形式で圧縮されている動画や画像にはあまり効果はありませんが、ソースコードの類には多少効くはず。一時ファイルを経由するのが面倒なので、オンザフライに読み書きするように変更していますが、それ以外は前回までと同じ実装です。
引き続き検証環境はPython3.6+Windows 10 Pro、実装はPython3前提です。
もくじ:
スクリプト
今回のスクリプトを記載しておきます。メソッドの構成は前回と変わっていません。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 | import os import io import random import string import urllib from zipfile import ZipFile, ZIP_DEFLATED from datetime import datetime from azure.storage.blob import BlockBlobService class _blob_client: def __init__(self, conf): # check if the home directory path is valid self.path = conf["home_path"] if not os.path.isdir(conf["home_path"]): raise Exception("home directory is not found") # build client self.client = BlockBlobService( account_name=conf["account_name"], account_key=conf["account_key"]) # set proxy if enabled if conf["proxy_enabled"]: self.client.set_proxy(conf["proxy_addr"], conf["proxy_port"], user=conf["proxy_user"], password=conf["proxy_pass"]) # set container name with checking if conf["container"] in [x.name for x in self.client.list_containers()]: self.__container = conf["container"] else: raise Exception("invalid container name") def __metadata(self, path_): mtime_ = datetime.fromtimestamp(os.path.getmtime(path_)) return {"path": os.path.relpath(path_, self.path), "updated": mtime_.strftime('%Y-%m-%d, %H:%M:%S'), "size": "{}".format(os.path.getsize(path_))} def download(self, blob_name): # make local directory meta_ = self.client.get_blob_metadata( container_name=self.__container, blob_name=blob_name) relpath_ = meta_["path"].split("*")[0] file_path = os.path.join(self.path, urllib.parse.unquote(relpath_)) print("receiving blob: {}".format(blob_name)) if len(meta_["path"].split("*")) > 1: # use buffer to receive with zip extraction on the fly stream = io.BytesIO() self.client.get_blob_to_stream(container_name=self.__container, blob_name=blob_name, stream=stream) # read from stream with ZipFile(stream, mode="r", compression=ZIP_DEFLATED) as zf: zf.extractall(self.path) else: os.makedirs(os.path.dirname(file_path), exist_ok=True) self.client.get_blob_to_path(container_name=self.__container, blob_name=blob_name, file_path=file_path) # modify timestamp mtime_ = datetime.strptime(meta_["updated"], '%Y-%m-%d, %H:%M:%S') mtime_ = mtime_.timestamp() os.utime(file_path, (mtime_, mtime_)) def upload(self, local_path, compression=True): # check file path if not os.path.isfile(local_path): raise Exception("invalid file path: {}".format(local_path)) # generate blob name name_ = ''.join(random.choices( string.ascii_letters + string.digits, k=16)) # create blob from local file print("creating blob: {}...".format(name_)) meta_ = self.__metadata(local_path) meta_["path"] = urllib.parse.quote(meta_["path"]) if compression: # use buffer to send with zip compression on the fly stream = io.BytesIO() with ZipFile(stream, mode="w", compression=ZIP_DEFLATED) as zf: zf.write(local_path, os.path.relpath(local_path, self.path)) # upload to blob stream.seek(0) meta_["path"] += "*" self.client.create_blob_from_stream(container_name=self.__container, blob_name=name_, stream=stream, metadata=meta_) else: self.client.create_blob_from_path(container_name=self.__container, blob_name=name_, file_path=local_path, metadata=meta_) def fetch_remote(self): blob_info = [] print("getting blob list...") for blob in self.client.list_blobs(container_name=self.__container): meta_ = self.client.get_blob_metadata(container_name=self.__container, blob_name=blob.name) if meta_ is None: print("skip blob {} due to missing metadata".format(blob.name)) continue blob_info.append({"name": blob.name, "path": urllib.parse.unquote(meta_["path"].split("*")[0]), "updated": meta_["updated"], "size": meta_["size"]}) return blob_info def fetch_local(self): file_info = [] for root, dirs, files in os.walk(self.path): for file_name in files: file_path = os.path.join(root, file_name) file_info.append(self.__metadata(file_path)) return file_info def clear(self, blob_name=None): blobs = [x.name for x in self.client.list_blobs(self.__container)] if blob_name is not None: blobs = [x for x in blobs if x == blob_name] for blob in blobs: print("removing blob: {}".format(blob)) self.client.delete_blob(container_name=self.__container, blob_name=blob) |
ファイルを圧縮して転送する
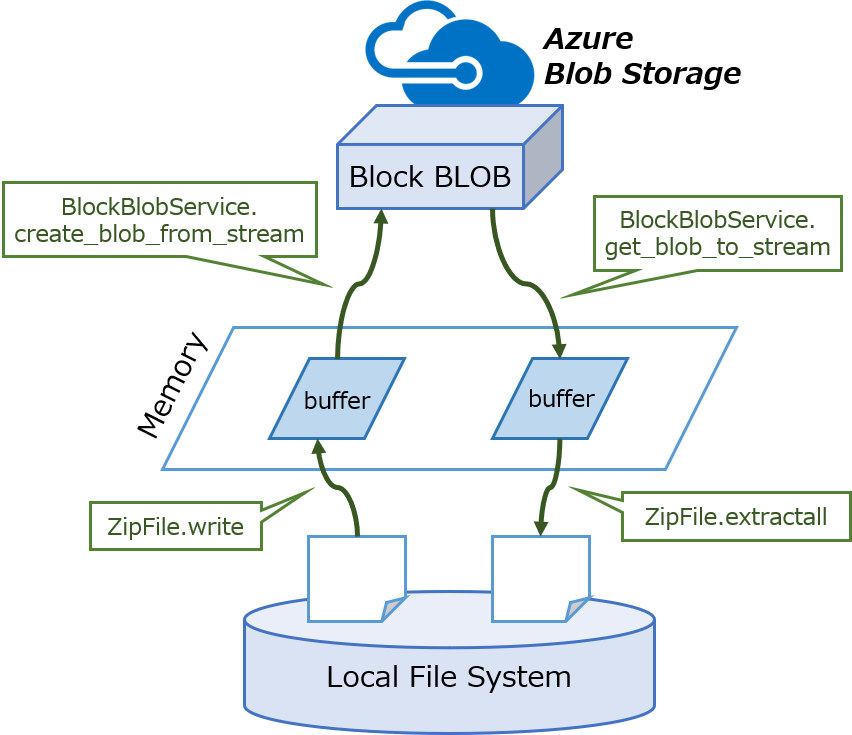
一時的にZIP書庫ファイルを作成するやり方もありますが、制御が面倒くさくなるのでio.BytesIO()を使ってメモリ上に確保してしまいます。
PythonでWebアプリケーションを作る場合にけっこう使われるやり方なので、他のREST APIを使うときも役立つかも知れません。
なお、ioモジュールはPython3世代で仕様変更が入っているため、今回のコードはPython2では動きません。たしかPython2ではString.StringIO()を使っていた記憶がありますが今回は触れません。
アップロード
おなじみzipfileモジュールでローカルのファイルを圧縮します。
zipfile.ZipFileはファイルシステム上の実体のあるファイルだけでなく、file-like objectを受け付けるのでここにByteIOストリームを渡します。
# こういう柔軟なところがPythonの良さですね。
圧縮された結果をBlockBlobService.create_blob_from_streamメソッドを使ってアップロードします。
1 2 3 4 5 6 7 8 9 10 11 12 | # use buffer to send with zip compression stream = io.BytesIO() with ZipFile(stream, mode="w", compression=ZIP_DEFLATED) as zf: zf.write(local_path, os.path.relpath(local_path, self.path)) # upload to blob stream.seek(0) meta_["path"] += "*" self.client.create_blob_from_stream(container_name=self.__container, blob_name=name_, stream=stream, metadata=meta_) |
また、圧縮されていることを示すためにメタデータに書くパスにアスタリスク*を付加しています。別途フラグを作っても良いのですが、面倒だったので。
ダウンロード
圧縮付きのBLOBをダウンロードする際には、メモリ上へダウンロードした後に解凍をかけます。
圧縮付きであるか否かの判定はメタデータのパス(アスタリスクが含まれるか否か)で判別します。
1 2 3 4 5 6 7 8 9 | if len(meta_["path"].split("*")) > 1: # use buffer to receive with zip extraction stream = io.BytesIO() self.client.get_blob_to_stream(container_name=self.__container, blob_name=blob_name, stream=stream) # read from stream with ZipFile(stream, mode="r", compression=ZIP_DEFLATED) as zf: zf.extractall(self.path) |
途中のディレクトリはZIP書庫解凍時に暗黙的に作成されるので、os.makedirs()を省略しています。
差分のみのファイル転送
ここでは差分を判定して、不要な転送を防ぐ例を記載しておきます。差分といってもファイル単位になりますが、BLOBのメタデータには更新日時などの属性を記録しているので、これらを比較して異なるもののみを対象にアップロード・ダウンロードします。
アップロード
ローカルにあるファイル、所定コンテナ内のBLOBは、それぞれ_blob_client.fetch_localメソッドと_blob_client.fetch_remoteメソッドで取得できます。
それぞれ構成要素はリストに格納されているので、リスト要素を比較することで、BLOBに記録された更新日時よりも新しいローカルファイル、またはまだアップロードされていないローカルファイルをアップロードの対象とします。
ついでに、より新しいファイルのアップロードにより不要になったBLOBは削除します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | from traceback import print_exc from blobclient import _blob_client def upload_diff(conf): try: # function for parse string as datetime from datetime import datetime def _format(dt_str): return datetime.strptime(dt_str, '%Y-%m-%d, %H:%M:%S') client = _blob_client(conf) local_ = client.fetch_local() remote_ = client.fetch_remote() upload_files = [] removable_blobs = [] # debug print print("local ----") for item in local_: print(item) print("remote ---") for item in remote_: print(item) import copy blobs = copy.deepcopy(remote_) for item in remote_: del item["name"] # find difference need to be uploaded for file_ in local_: # find file has not been uploaded if file_ not in remote_: dup = [x for x in blobs if x["path"] == file_["path"]] if len(dup) > 0: # find the same named file(s) but updated for duplicated in dup: if _format(file_["updated"]) > _format(duplicated["updated"]): upload_files.append(file_["path"]) removable_blobs.append(duplicated["name"]) else: upload_files.append(file_["path"]) # upload files for file_path in upload_files: print("upload: {}".format(file_path)) client.upload(os.path.join(client.path, file_path)) # remove blobs for blob in removable_blobs: print("remove: {}".format(blob)) client.clear(blob) except: print_exc() |
この実装では当たり前ですが、同じファイルの名前を変えた場合には別のファイルとしてカウントされるので対応できません。ちゃんとやろうとするとハッシュを計算するのがより正確な気がしますが、まあ今回は脱線になるので割愛。
実行結果は下記のようになります。ちょっと長いですが、試してみるとローカルで更新されていてアップロードされていないものが対象になっていることがわかると思います。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | > python client.py getting blob list... local ---- {'path': '新しいテキスト ドキュメント.txt', 'updated': '2017-01-06, 18:26:25', 'size': '10740'} {'path': 'subdir1\\image01.jpg', 'updated': '2013-10-26, 05:01:29', 'size': '254888'} {'path': 'subdir1\\subdir2\\textfile1.txt', 'updated': '2017-03-01, 05:24:51', 'size': '1990'} remote --- {'name': 'CH0BMZI15WjfMgeE', 'path': 'subdir1\\subdir2\\textfile1.txt', 'updated': '2017-03-01, 05:24:51', 'size': '1990'} {'name': 'gCYtJ2oF87JWVcdY', 'path': '新しいテキスト ドキュメント.txt', 'updated': '2017-01-05, 22:35:51', 'size': '5370'} {'name': 'tVYj46KcUlHgzrCL', 'path': 'subdir1\\image01.jpg', 'updated': '2013-10-26, 05:01:29', 'size': '254888'} upload: 新しいテキスト ドキュメント.txt creating blob: BbrhdaKEre2kH4Uy... remove: gCYtJ2oF87JWVcdY removing blob: gCYtJ2oF87JWVcdY |
ダウンロード
内容を比較することろはアップロードの場合と基本的には同じです。パスが重複した場合は、更新日時の新しいBLOBがあった場合のみダウンロードの対象とします。
ローカルファイルの場合、パスが同じならば後にダウンロードしたものにより重複したファイルが上書きされるので、明示的に削除する必要はありません。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | from traceback import print_exc from blobclient import _blob_client def download_diff(conf): try: # function for parse string as datetimes from datetime import datetime def _format(dt_str): return datetime.strptime(dt_str, '%Y-%m-%d, %H:%M:%S') client = _blob_client(conf) local_ = client.fetch_local() remote_ = client.fetch_remote() download_blobs = [] # debug print print("local ----") for item in local_: print(item) print("remote ---") for item in remote_: print(item) # find difference need to be downloaded for blob in remote_: temp = {"path": blob["path"], "updated": blob["updated"], "size": blob["size"]} if temp not in local_: dup = [x for x in local_ if x["path"] == temp["path"]] if len(dup) > 0: # find the same named file(s) but updated for duplicated in diff: if _format(temp["updated"]) > _format(duplicated["updated"]): download_blobs.append(blob["name"]) else: download_blobs.append(blob["name"]) # download blobs (overwritten if local file exists) for blob in download_blobs: print("download: {}".format(blob)) client.download(blob) except: print_exc() |
実行結果の例は下記のようになります。ローカルに存在せず、BLOBとしてアップロードされているもののみをダウンロードしています。
1 2 3 4 5 6 7 8 9 10 11 12 13 | > python client.py getting blob list... local ---- {'path': 'image01.jpg', 'updated': '2012-09-08, 02:57:46', 'size': '414717'} {'path': 'subdir1\\image01.jpg', 'updated': '2013-10-26, 05:01:29', 'size': '254888'} {'path': 'subdir1\\subdir2\\textfile1.txt', 'updated': '2017-01-01, 05:24:51', 'size': '1990'} remote --- {'name': 'BEpEpYdKrks93n8n', 'path': 'image01.jpg', 'updated': '2012-09-08, 02:57:46', 'size': '414717'} {'name': 'CH0BMZI15WjfMgeE', 'path': 'subdir1\\subdir2\\textfile1.txt', 'updated': '2017-01-01, 05:24:51', 'size': '1990'} {'name': 'gCYtJ2oF87JWVcdY', 'path': '新しいテキスト ドキュメント.txt', 'updated': '2017-01-05, 22:35:51', 'size': '5370'} {'name': 'tVYj46KcUlHgzrCL', 'path': 'subdir1\\image01.jpg', 'updated': '2013-10-26, 05:01:29', 'size': '254888'} download: gCYtJ2oF87JWVcdY receiving blob: gCYtJ2oF87JWVcdY |
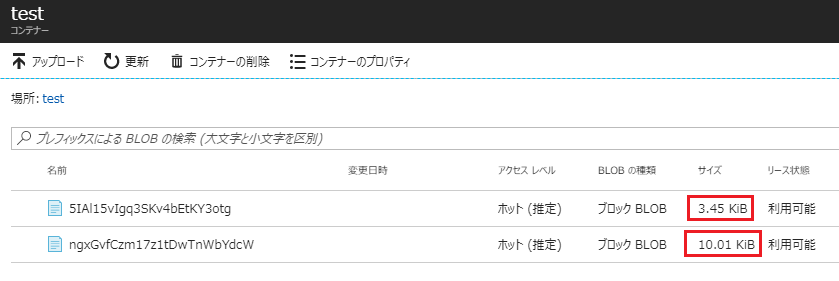
実際に試してみると、心持ち圧縮されている気がしますね。
# BLOB名は違いますが同じファイルの圧縮・非圧縮バージョン↓