Apache Hadoopの大本命、完全分散モード(クラスタ)を構築してみます。
疑似分散モードのように単一のノード内でマスター、スレーブの機能をJVMの上に立ち上げるのではなく、実際に各機能についてノードを分けて構築するタイプの構成です。MapReduce側はYARN(MRv2)を使います。
ClouderaとかHorton Worksが提供しているような、Hadoopフレームワークという便利なものが世の中にはありますが、まあ勉強のため素のYARNを構築してみましょう。
サービスとして常駐させるなどいろいろやり方はありますが、ここでは恐らく一番シンプルと思われるやり方(シェルスクリプトで逐一スタートする)で行きます。
おおよその流れは図のようなものです。
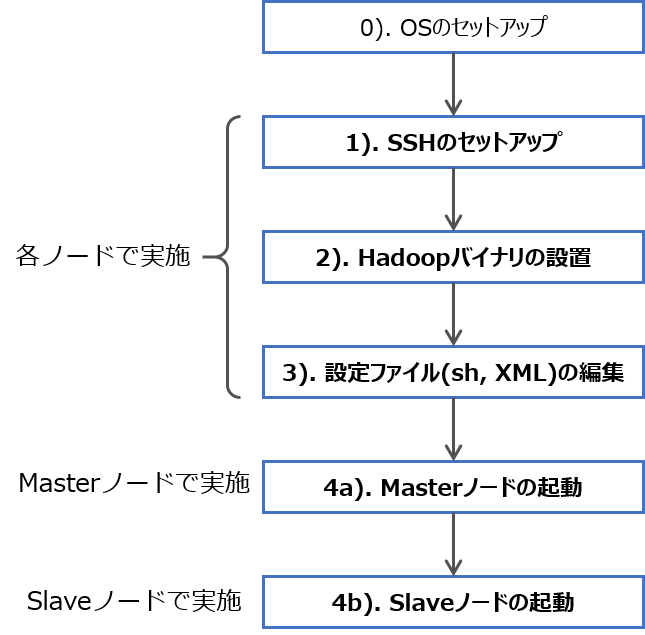
構成例
ここでは3台のLinuxマシンを使って構築することにしました。ここで使用している共通的な構成は以下の通り。バージョンやOSは特にこだわりがあるわけではなく、たまたまです。必要に応じて読み替えて下さい。
| 項目 | 値 | 備考 |
|---|---|---|
| Hadoopバージョン | 2.6.5 | |
| JDKバージョン | 8 | OpenJDK 1.8.0 |
| 実行ユーザ | user | sudo権限あり |
| OS | Ubuntu (Server) | 16.04, 64ビット |
| インストールパス | /usr/local/hadoop |
また、それぞれ同じサブネットLANに接続した(Hyper-V上の)仮想マシンとして構築し、アドレス・ホスト名を次のように設定することにします。MasterはSlaveと兼用できます。
- Masterノード (x1台)
- IPアドレス 192.168.100.10, ホスト名 ha1
- Slaveノード (x2台)
- IPアドレス 192.168.100.11, ホスト名 ha2
- IPアドレス 192.168.100.12, ホスト名 ha3
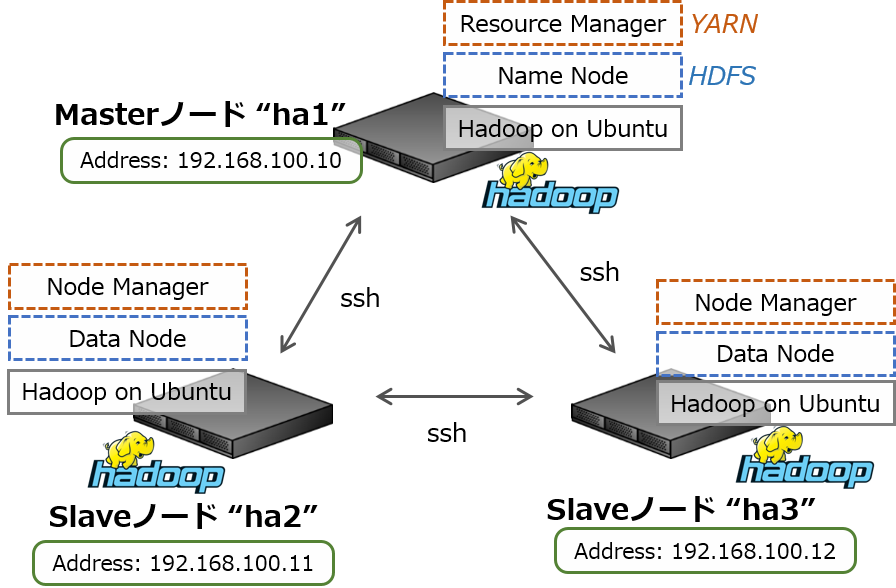
MasterノードにはYARNのResource managerとHDFSのName nodeを、SlaveにはNode managerとdata nodeを稼働させます。
クラスタの準備
クラスタの構築に必要な前提となる設定です。
JDKのインストール
HadoopはJava仮想マシン上で動作しますので、JDKをインストールしておく必要があります。
ここでは以下のコマンドでインストールしました。
1 2 3 | # 全ノードで実施 (sudo apt update) sudo apt install openjdk-8-jdk |
SSH公開鍵の作成と配布
HadoopクラスタはSSH経由で相互にコミュニケーションしますので、互いに自動的に認証できるよう設定する必要があります。
そのためには、まず各ノードでキーペアを作成します。
1 2 | # 全ノードで実施 ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa |
SSHフォルダ~/.sshに秘密鍵と公開鍵ファイルid_rsa.pubが作成されます。
このように各ノードで自身の公開鍵を作成し、ログイン先の他ノードに登録しておく必要があります。SCPなどでクライアントにダウンロードしたあと各ノードにコピーするか、またはssh-copy-idコマンドを使います。
公開鍵ファイルをSCPなどでコピーする場合、ファイルの内容をauthorized_keysファイルに追記することで登録できます。
1 2 | # 全ノードで実施 cat (各ノードのid_rsa.pub ファイル) >> ~/.ssh/authorized_keys |
またはssh-copy-idコマンドを使います。
1 2 3 4 5 | # 全ノードで実施、以下はMasterノードでの例 # ha2へ登録、メッセージに従って必要事項を入力 ssh-copy-id user@192.168.100.11 # ha3へ登録 ssh-copy-id user@192.168.100.12 |
SSHのキー確認をスキップするよう設定を変更します。
SSHフォルダ~/.sshにconfigファイルを作成して下記の内容で保存します。
1 2 3 4 5 6 7 | # 全ノードで実施 $ vi ~/.ssh/config # 以下の内容で新規作成 Host * UserKnownHostsFile /dev/null StrictHostKeyChecking no LogLevel quiet |
hostsファイルの編集
ホスト名を解決させたいので、hostsファイルを設定しておきます。
DNSを用意している場合など、不要ならばこのステップは省略できます。
1 2 3 4 5 | # 全ノードで実施、以下はMasterノードでの例 $ sudo vi /etc/hosts # 以下を追記して保存 192.168.100.11 ha2 192.168.100.12 ha3 |
注意点は、(少なくともMasterノードでは)ローカルホストについてレコードを重複させないこと。
一般的なhostsファイルの書き方として、ループバック(127.0.0.1)と別にLAN上の自アドレスに対してホスト名を書いても問題になることはありませんが、この環境ではエラーになりSlaveノードがMasterノードへ接続できません。
例えば、以下の書き方はNGです。
1 2 3 4 5 6 7 | $ sudo vi /etc/hosts 127.0.0.1 localhost 127.0.0.1 ha1 192.168.100.10 ha1 ←この行はダメ 192.168.100.11 ha2 192.168.100.12 ha3 |
Hadoopのインストール
バイナリをダウンロード、設置します。
ダウンロードと設置
使用するバージョンに応じて、tarballをダウンロードしてきます。
URLはApache Hadoop公式を参照して好きなミラーサイトを選んで下さい。
この例では、解凍したのち/var/local/へ移動、さらに/usr/local/hadoopにリンクを張っています。
1 2 3 4 5 6 7 8 | # 全ノードで実施 # ダウンロードと解凍 wget http://ftp.jaist.ac.jp/pub/apache/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz tar zxvf hadoop-2.6.5.tar.gz # 設置 sudo mv hadoop-2.6.5 /var/local/hadoop-2.6.5 sudo ln -s /var/local/hadoop-2.6.5 /usr/local/hadoop sudo chown -R user /var/local/hadoop-2.6.5 |
上の例では、/varに一式を配置しているので、操作にはルート権限が必要ですが、もちろんユーザ領域に配置する場合は不要です。
実行バイナリや設定ファイルが含まれているので、Hadoopを起動するユーザに実行権限と編集(書き込み)権限を設定しておいて下さい。
環境変数の設定
Hadoopが依存している変数を渡すため、hadoop-config.shスクリプト先頭に追記し、各環境変数を設定します。
1 | vi /usr/local/hadoop/libexec/hadoop-config.sh |
追記する内容は以下。
1 2 3 4 5 6 7 8 9 10 | # 全ノードで実施 export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export HADOOP_HOME=/usr/local/hadoop export HADOOP_PREFIX=/usr/local/hadoop export HADOOP_COMMON_HOME=/usr/local/hadoop export HADOOP_HDFS_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=/usr/local/hadoop export HADOOP_YARN_HOME=/usr/local/hadoop export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop export YARN_CONF_DIR=$HADOOP_PREFIX/etc/hadoop |
JAVA_HOMEはJDKがインストールされたパスです。
XML設定ファイルの上書き
設定はXMLファイルで記載します。最低限、core-site.xmlファイルとhdfs-site.xmlファイルを設定しておけば動くはず。
1 2 3 | # 全ノードで実施 vi /usr/local/hadoop/etc/hadoop/core-site.xml vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml |
core-site.xmlファイルにはHDFSのName nodeを記載します。したがって、ここで記載するアドレスはMasterノードのもの。もちろん設定してあればホスト名でもOK。
1 2 3 4 5 6 | <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.100.10:9000</value> </property> </configuration> |
hdfs-site.xmlファイルには、各ノードでname node/data nodeのデータ格納用に使うパスなどを記載します。パスはそれぞれのノードの役割に応じて指定して下さい。
最後のdfs...ip-hostname-checkプロパティはname node(Masterノード)のhdfs-site.xmlファイルにのみ記載するのでも構いません。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.data.dir</name> <value>/var/lib/hadoop/data</value> </property> <property> <name>dfs.name.dir</name> <value>/var/lib/hadoop/name</value> </property> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value> </property> </configuration> |
HDFSの構築
各ノードでHDFSに使用するディレクトリを作成しておきます。Hadoopの実行ユーザで編集できるよう設定して下さい。パスはhdfs-site.xmlに書いたものに揃えます。
1 2 3 4 5 6 | # Masterノードで実行 sudo mkdir -p /var/lib/hadoop/name sudo chown -R user /var/lib/hadoop # Slaveノードで実行 sudo mkdir -p /var/lib/hadoop/data sudo chown -R user /var/lib/hadoop |
また、HDFSのネームノードを初期化しておきましょう。
1 2 | # Masterノードで実行 /usr/local/hadoop/bin/hdfs namenode -format |
この時点でHDFSを起動できます。以下のようにシェルスクリプトを実行して下さい。
1 2 3 4 | # Masterノード(Name Node)で実行 /usr/local/hadoop/sbin/hadoop-daemon.sh start namenode # Slaveノード(Data Node)で実行 /usr/local/hadoop/sbin/hadoop-daemon.sh start datanode |
正常に構築できていれば、MasterノードのURL(http://192.168.100.10:50070/)にアクセスしたときに、HDFSの管理UIが表示されるはず。
各ノードでjpsコマンドを実行すると、担当プロセスが立ち上がっているか確認できます。
YARNの構築
YARNクラスタを構築するには、さらにyarn-site.xmlファイルを編集し、MasterノードのIPアドレスを指定します。
1 2 | # 全ノードで実施 vi /usr/local/hadoop/etc/hadoop/yarn-site.xml |
1 2 3 4 5 6 | <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.100.10</value> </property> </configuration> |
設定ファイルを保存し、各YARNノードを起動します。
1 2 3 4 | # Masterノードで実行(Resource Manager) /usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager # Slaveノードで実行(Node Manager) /usr/local/hadoop/sbin/yarn-daemon.sh start nodemanager |
正常に構築できていれば、MasterノードのURL(http://192.168.100.10:8088/)にアクセスしたときに、YARNの管理UI (Resource Manager Web UI)が表示されるはず。